

Advanced Enterprise Search Solutions using Elasticsearch or Opensearch
Considering using Elasticsearch or Opensearch for your Enterprise Search solution? Before you make your decision, let’s show you what SearchBlox can do.








We work with industry leaders.
More than 600 enterprises — some of the biggest names in government, healthcare and financial services — use SearchBlox to power their insight engine. SearchBlox is an production-grade, out-of-the-box Enterprise Search product built on top of the core Elasticsearch / Opensearch engine.
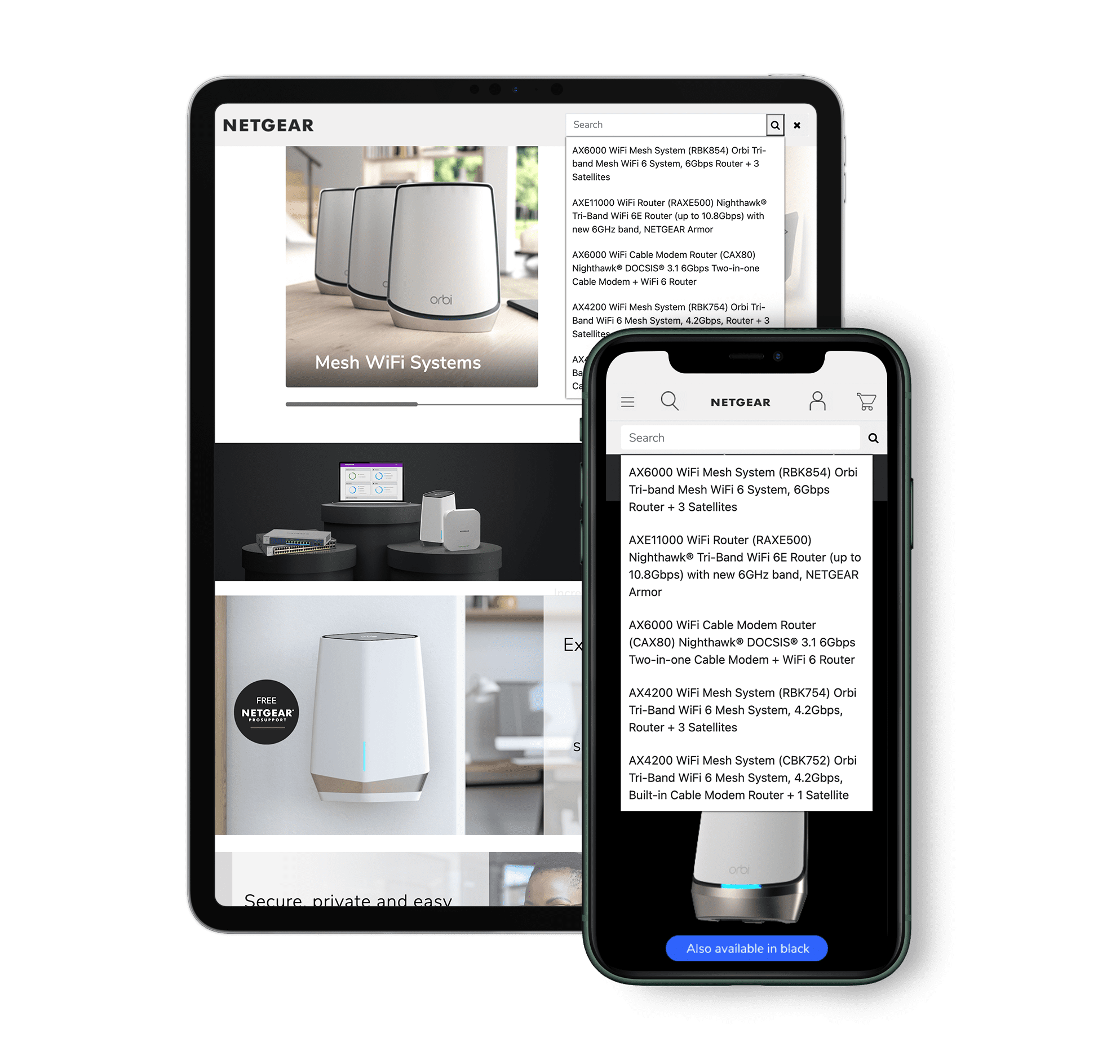
300+ data connectors, supports 37 languages and processing for 40+ document formats.
No external dependencies; SearchBlox is bundled with Opensearch as the default.
Improve digital experience instantly. Rapid deployment for on-prem setups takes 15 minutes or less.
Fully compatible with solutions like Elastic Cloud and Amazon OpenSearch Service.
Flexible integration ability with additional trusted Enterprise Security systems like LDAP.
Includes flexible, native, AI-driven NLP capabilities that support any organization or industry.
24×7 Platinum-Level Support with SLA gives teams confidence and ongoing peace of mind.
No hidden surprises or vendor lock-in. Remain confident in our product and support with transparent pricing.
Our search UI templates get clients up and running fast—no additional development required.

Advanced features, customer support, and additional security come standard.
Deciding to build vs. buy your Elasticsearch solution? Here are the real questions to ask:
How long will this take to build? How soon can we deploy a solution to production?
Out of the box, SearchBlox delivers a working solution faster and ensures you don’t have to worry about keeping up with the latest technology.
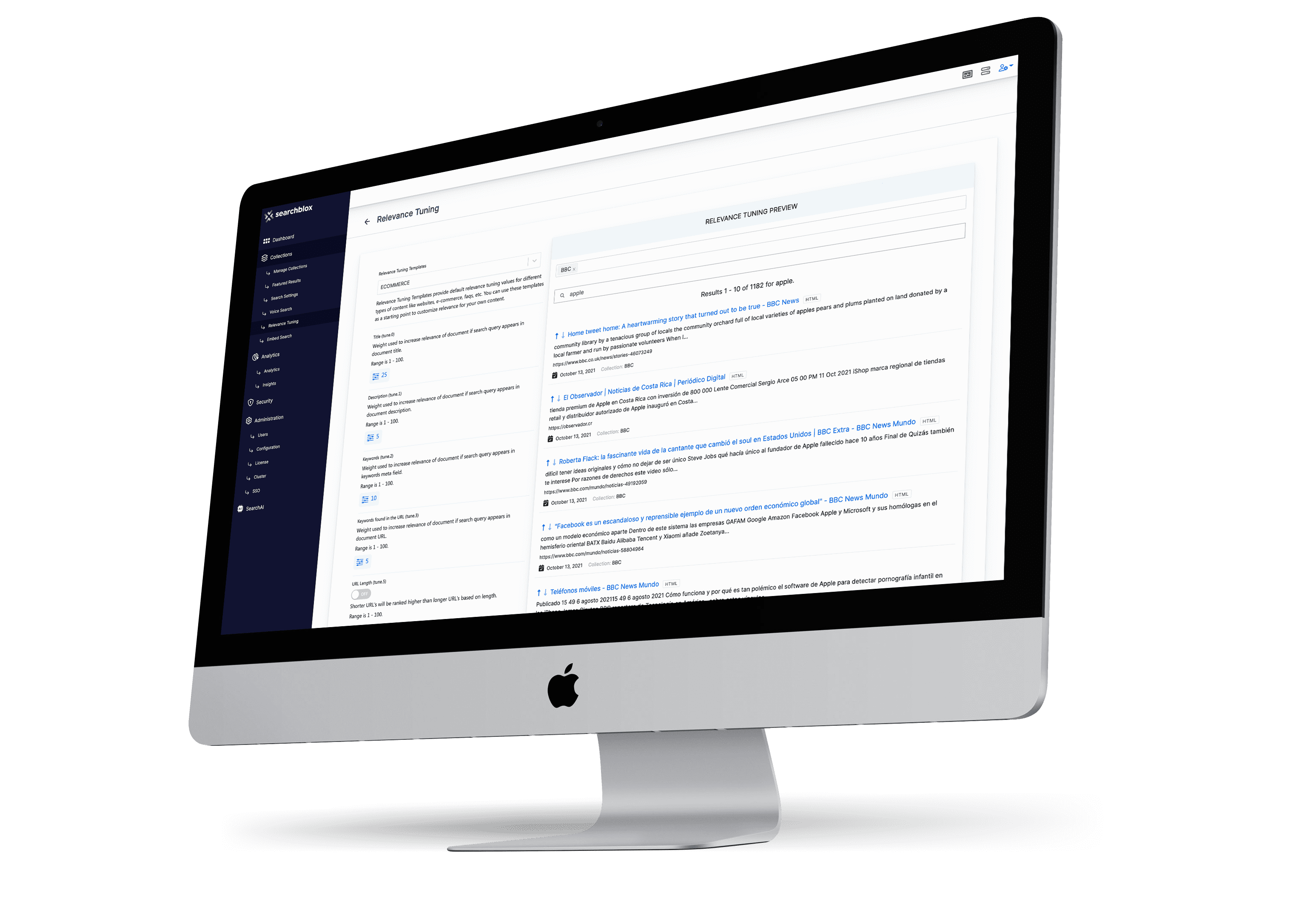

What is the total cost of building and maintaining this for 3 years vs. paying SearchBlox to do it?
The costs add up quickly when companies choose to build it themselves. Maintenance, support, operational costs and more create a total cost of ownership (TCO) that is typically 2x higher than SearchBlox. Proprietary solutions that charge high licensing fees and require professional services to configure can easily cost 3x as much as SearchBlox.
If we build it ourselves, will we be able to stay current with the latest developments in search or does my organization risk falling behind?
It can be tempting to build using Open Source technology. But building and maintaining a comparable enterprise search experience will take longer and cost more, period.

Do I need a data scientist to start using AI NLP or are there ready-to-use integrations or applications that I can pick and choose?
SearchBlox empowers every content manager with the ability to start putting AI and NLP to work, improving search and eliminating manual tasks. No data scientists required.
SearchBlox came loaded with all the enterprise features we were looking for. This woud have taken us a long time to build ourselves and deploy in production.
IT Director, Fortune 500 Financial Services Organization
Deployment
Elasticsearch and Opensearch can be deployed either on your own hardware or in the cloud. There are also several options to get Elasticsearch/ Opensearch service via a managed service provider like Amazon Web Services or the Google Cloud platform or Elastic Cloud.
New to Elasticsearch?
Here’s a basic overview.
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java and is dual-licensed under the source-available Server Side Public License and the proprietary Elastic License.
Opensearch is a community-driven, open source search and analytics suite derived from Apache 2.0 licensed Elasticsearch 7.10.2 & Kibana 7.10.2. Both Elasticsearch and Opensearch provide similar/comparable functionality.
We got a ready-to-use, Elasticsearch-based enterprise search solution up and running in 1 day.
Tech Lead, Marketing Agency
Get started in minutes for free with Search as a Service (SaaS) products.
Or enjoy all the efficiencies of the cloud by choosing our Fully Managed Enterprise Search.
Advanced Enterprise Search Solutions using Elasticsearch or Opensearch
Considering using Elasticsearch or Opensearch for your Enterprise Search solution? Before you make your decision, let’s show you what SearchBlox can do.
We work with industry leaders.
More than 600 enterprises — some of the biggest names in government, healthcare and financial services — use SearchBlox to power their insight engine. SearchBlox is an production-grade, out-of-the-box Enterprise Search product built on top of the core Elasticsearch / Opensearch engine.
300+ data connectors, supports 37 languages and processing for 40+ document formats.
No external dependencies; SearchBlox is bundled with Opensearch as the default.
Improve digital experience instantly. Rapid deployment for on-prem setups takes 15 minutes or less.
Fully compatible with solutions like Elastic Cloud and Amazon OpenSearch Service.
Flexible integration ability with additional trusted Enterprise Security systems like LDAP.
Includes flexible, native, AI-driven NLP capabilities that support any organization or industry.
24×7 Platinum-Level Support with SLA gives teams confidence and ongoing peace of mind.
No hidden surprises or vendor lock-in. Remain confident in our product and support with transparent pricing.
Our search UI templates get clients up and running fast—no additional development required.
Advanced features, customer support, and additional security come standard.
Deciding to build vs. buy your Elasticsearch solution? Here are the real questions to ask:
How long will this take to build? How soon can we deploy a solution to production?
Out of the box, SearchBlox delivers a working solution faster and ensures you don’t have to worry about keeping up with the latest technology.
What is the total cost of building and maintaining this for 3 years vs. paying SearchBlox to do it?
The costs add up quickly when companies choose to build it themselves. Maintenance, support, operational costs and more create a total cost of ownership (TCO) that is typically 2x higher than SearchBlox. Proprietary solutions that charge high licensing fees and require professional services to configure can easily cost 3x as much as SearchBlox.
If we build it ourselves, will we be able to stay current with the latest developments in search or does my organization risk falling behind?
It can be tempting to build using Open Source technology. But building and maintaining a comparable enterprise search experience will take longer and cost more, period.
Do I need a data scientist to start using AI NLP or are there ready-to-use integrations or applications that I can pick and choose?
SearchBlox empowers every content manager with the ability to start putting AI and NLP to work, improving search and eliminating manual tasks. No data scientists required.
SearchBlox came loaded with all the enterprise features we were looking for. This woud have taken us a long time to build ourselves and deploy in production.
IT Director, Fortune 500 Financial Services Organization
New to Elasticsearch?
Here’s a basic overview.
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java and is dual-licensed under the source-available Server Side Public License and the proprietary Elastic License.
Opensearch is a community-driven, open source search and analytics suite derived from Apache 2.0 licensed Elasticsearch 7.10.2 & Kibana 7.10.2. Both Elasticsearch and Opensearch provide similar/comparable functionality.
Deployment
Elasticsearch and Opensearch can be deployed either on your own hardware or in the cloud. There are also several options to get Elasticsearch/ Opensearch service via a managed service provider like Amazon Web Services or the Google Cloud platform or Elastic Cloud.
We got a ready-to-use, Elasticsearch-based enterprise search solution up and running in 1 day.
Tech Lead, Marketing Agency

Get started in minutes for free with Search as a Service (SaaS) products.
Or enjoy all the efficiencies of the cloud by choosing our Fully Managed Enterprise Search.
You’re in excellent company.
More than 600 enterprises — some of the biggest names in government, healthcare and financial services — use SearchBlox to power their insight engine and and AI-driven customer tools.

























You’re in excellent company.
More than 600 enterprises — some of the biggest names in government, healthcare and financial services — use SearchBlox to power their insight engine and and AI-driven customer tools.