NEW! SearchBlox is now an Adobe Gold Technology Partner - Add Agentic Search to Adobe Experience Manager I Get Started.




NEW! SearchBlox is now an Adobe Gold Technology Partner - Add Agentic Search to Adobe Experience Manager I Get Started.
NEW! SearchBlox is now an Adobe Gold Technology Partner - Add Agentic Search to Adobe Experience Manager I Get Started.


Retrieval Augmented Generation — RAG 101
RAG 101
Retrieval Augmented Generation — RAG 101
The Complete Guide
The Complete Guide
The Complete Guide
to
to
to
RAG + LLM
RAG + LLM
RAG + LLM
Tap into new value from your existing data by adding retrieval augmented generation.
Tap into new value from your existing data by adding retrieval augmented generation.
Tap into new value from your existing data by adding retrieval augmented generation.
Eliminate hallucinations to deliver complete, context-aware and trusted responses from your data.
Eliminate hallucinations to deliver complete, context-aware and trusted responses from your data.
Seamlessly integrate RAG chatbots with current applications to enable faster access to your information.
Seamlessly integrate RAG chatbots with current applications to enable faster access to your information.
Deploy RAG on your own data center, or SearchBlox’s secure fully managed cloud infrastructure.
Deploy RAG on your own data center, or SearchBlox’s secure fully managed cloud infrastructure.
Introduction
Introduction
Introduction
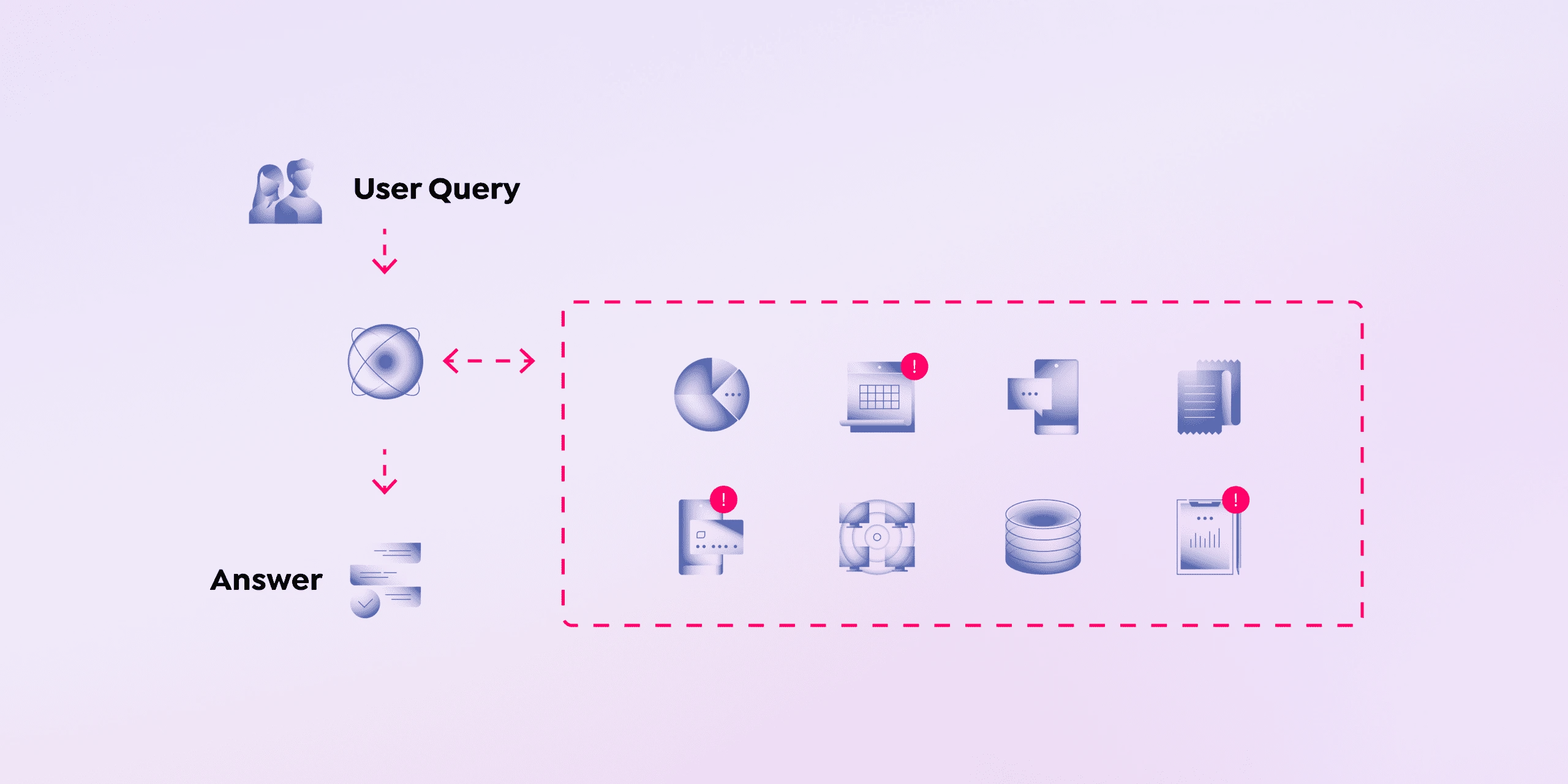
Make all user interactions with your data relevant and context-aware. Go beyond basic retrieval to providing contextual, personalized and up-to-date information from organizational data sources – wherever it lives.
Make all user interactions with your data relevant and context-aware. Go beyond basic retrieval to providing contextual, personalized and up-to-date information from organizational data sources – wherever it lives.
Make all user interactions with your data relevant and context-aware. Go beyond basic retrieval to providing contextual, personalized and up-to-date information from organizational data sources – wherever it lives.
As the adoption of Generative AI models like GPT-4, Llama 3 and Gemini increases, so does the increased scrutiny over the credibility of their responses. Large language models (LLMs), while impressive in their ability to generate highly coherent answers, are only as smart as the data used to train them. When questions fall outside their training sets, LLMs tend to regurgitate random facts or inaccurate information, otherwise known as “hallucination.”
As the adoption of Generative AI models like GPT-4, Llama 3 and Gemini increases, so does the increased scrutiny over the credibility of their responses. Large language models (LLMs), while impressive in their ability to generate highly coherent answers, are only as smart as the data used to train them. When questions fall outside their training sets, LLMs tend to regurgitate random facts or inaccurate information, otherwise known as “hallucination.”
We can use Retrieval Augmented Generation (RAG) to address the limitations of large language models – incorporating real-time, reliable information grounded in the latest internal data. RAG integrates your organization’s vast knowledge base—documents, databases, or any other relevant data source—with the LLM, enabling your AI applications to scour through specific data sets outside of its training domain.
We can use Retrieval Augmented Generation (RAG) to address the limitations of large language models – incorporating real-time, reliable information grounded in the latest internal data.
RAG integrates your organization’s vast knowledge base—documents, databases, or any other relevant data source—with the LLM, enabling your AI applications to scour through specific data sets outside of its training domain.
RAG is transforming the way businesses leverage their most valuable asset – knowledge. According to Gartner, the volume of synthetically generated marketing messages is set to explode in the coming years. RAG can play a pivotal role in ensuring these communications are engaging, factually correct, and relevant to each customer, enhancing trust and driving business outcomes.
RAG is transforming the way businesses leverage their most valuable asset – knowledge. According to Gartner, the volume of synthetically generated marketing messages is set to explode in the coming years. RAG can play a pivotal role in ensuring these communications are engaging, factually correct, and relevant to each customer, enhancing trust and driving business outcomes.
Imagine a customer service chatbot that instantly pulls up the latest product specifications or a healthcare AI assistant that references current medical guidelines. RAG is not just about more intelligent AI; it’s about unlocking a new level of efficiency, personalization, and reliability across industries.
Imagine a customer service chatbot that instantly pulls up the latest product specifications or a healthcare AI assistant that references current medical guidelines. RAG is not just about more intelligent AI; it’s about unlocking a new level of efficiency, personalization, and reliability across industries.
So, buckle up as we dive into the tech behind RAG and discover how it’s set to revolutionize the AI landscape.
So, buckle up as we dive into the tech behind RAG and discover how it’s set to revolutionize the AI landscape.

Discover What’s Possible
Your enterprise data — contextual, personalized and relevant with SearchAI
Discover What’s Possible
Your enterprise data — contextual, personalized and relevant with SearchAI
Discover What’s Possible
Your enterprise data — contextual, personalized and relevant with SearchAI
What is Retrieval Augmented Generation (RAG)?
What is RAG?
RAG instills more confidence in your Gen AI deployments. It ensures your AI models uses the most recent and relevant information for smarter, more trustworthy responses.
RAG instills more confidence in your Gen AI deployments. It ensures your AI models uses the most recent and relevant information for smarter, more trustworthy responses.
RAG instills more confidence in your Gen AI deployments. It ensures your AI models uses the most recent and relevant information for smarter, more trustworthy responses.

Retrieval Augmented Generation (RAG) is a technique that enhances the capabilities of large language models (LLMs) by combining them with external information retrieval systems. This allows LLMs to access a wider range of information beyond their initial training data, resulting in more accurate, reliable, and contextually relevant responses.
Retrieval Augmented Generation (RAG) is a technique that enhances the capabilities of large language models (LLMs) by combining them with external information retrieval systems. This allows LLMs to access a wider range of information beyond their initial training data, resulting in more accurate, reliable, and contextually relevant responses.
Think of retrieval augmented generation as a bridge between your AI’s vast potential and the specific knowledge that resides within your organization, enabling it to answer questions about the latest product specifications, internal company policies, industry-specific regulations, etc
Think of retrieval augmented generation as a bridge between your AI’s vast potential and the specific knowledge that resides within your organization, enabling it to answer questions about the latest product specifications, internal company policies, industry-specific regulations, etc
RAG retrieves relevant documents or sections from a large database using retrieval systems based on dense vector representations. These mechanisms enable efficient storage and retrieval of information from a vector database. For a private LLM, incorporating domain-specific knowledge is crucial in enhancing the retrieval accuracy of RAG, especially in adapting it to a variety of tasks and answering highly specific questions in an ever-changing context, distinguishing between open-domain and closed-domain settings for added security and reliability.
RAG retrieves relevant documents or sections from a large database using retrieval systems based on dense vector representations. These mechanisms enable efficient storage and retrieval of information from a vector database. For a private LLM, incorporating domain-specific knowledge is crucial in enhancing the retrieval accuracy of RAG, especially in adapting it to a variety of tasks and answering highly specific questions in an ever-changing context, distinguishing between open-domain and closed-domain settings for added security and reliability.
Key Components of RAG
Key Components of RAG
The RAG acronym when expanded, exemplifies its two primary components: Retrieval & Augmented Generation
The RAG acronym when expanded, exemplifies its two primary components: Retrieval & Augmented Generation
The RAG acronym when expanded, exemplifies its two primary components: Retrieval & Augmented Generation
Retrieval
Retrieval
RAG begins with the identification phase where user prompts trigger data extraction from a designated knowledge base or any relevant external data sources. The retriever mechanism acts as a filter, meticulously selecting the most suitable information to accurately address a user’s query.
RAG begins with the identification phase where user prompts trigger data extraction from a designated knowledge base or any relevant external data sources. The retriever mechanism acts as a filter, meticulously selecting the most suitable information to accurately address a user’s query.
To ensure accuracy, the RAG’s retriever is constantly refined. This involves breaking down information into bite-sized chunks, fine-tuning embedding models to better capture meaning, and aligning queries with documents. This meticulous approach ensures the retriever pinpoints precisely the right information to address the query, like a seasoned researcher finding the perfect reference in a vast library.
To ensure accuracy, the RAG’s retriever is constantly refined. This involves breaking down information into bite-sized chunks, fine-tuning embedding models to better capture meaning, and aligning queries with documents. This meticulous approach ensures the retriever pinpoints precisely the right information to address the query, like a seasoned researcher finding the perfect reference in a vast library.

Augmented Generation
Augmented Generation
In the “generation phase”, the retrieved information is seamlessly integrated into the LLM’s prompt. The LLM, a sophisticated language model trained on vast datasets, then leverages this augmented prompt to generate a response.
In the “generation phase”, the retrieved information is seamlessly integrated into the LLM’s prompt. The LLM, a sophisticated language model trained on vast datasets, then leverages this augmented prompt to generate a response.
By combining its pre-existing knowledge with the context derived from the retrieved data, the LLM crafts an answer that is not only accurate and informative, but also contextually relevant and tailored to the specific query.
By combining its pre-existing knowledge with the context derived from the retrieved data, the LLM crafts an answer that is not only accurate and informative, but also contextually relevant and tailored to the specific query.
The generator can be further optimized through post-retrieval processing or fine-tuning to ensure that the generated text sounds natural and effectively leverages the retrieved documents.
The generator can be further optimized through post-retrieval processing or fine-tuning to ensure that the generated text sounds natural and effectively leverages the retrieved documents.
Best-in-Class RAG Solution
Give SearchBlox a try. Totally free
for 30 days.
Give SearchBlox a try. Totally free
for 30 days.
Empower your customers and employees with the contextual relevance of an LLM and the accuracy of RAG.

How RAG Works
How RAG Works
The Technology Behind Search and LLM’s
The Technology Behind Search and LLM’s
Under the hood, enterprise search or information retrieval is a complex and thorough process. Here’s a simplified overview of how it works.
Under the hood, enterprise search or information retrieval is a complex and thorough process. Here’s a simplified overview of how it works.

Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.

Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.

Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.

Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.

Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.

Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
Data Collection & Embedding
The process starts by gathering relevant data from various sources, including web pages. An embedding model then transforms this data into numerical vectors, capturing its semantic essence.
Vector Storage & Indexing
These vectors are stored in a vector database, which serves as a knowledge base for the RAG system. The vector database is indexed to enable efficient retrieval of relevant information.
Query Processing
When a user submits a query, the RAG system converts it into a vector representation using the same embedding model used for the knowledge base.
Retrieval of Relevant Information
The vectorized query is then used to search the vector database, identifying similar vectors that represent relevant information in the knowledge base.
Prompt Augmentation
The retrieved information is integrated with the original query, creating a more comprehensive prompt that includes relevant context.
Response Generation
The augmented prompt is fed into a large language model (LLM), which generates a personalized response incorporating the retrieved information.
The Role of AI in RAG
The Role of AI in RAG
RAG empowers your AI applications to embrace certainty when navigating through the complexities of your enterprise data.
RAG empowers your AI applications to embrace certainty when navigating through the complexities of your enterprise data.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
Machine Learning (ML)
ML algorithms play a crucial role in both the retrieval and generation phases. They refine the retrieval process by learning from user feedback and behavior, ensuring that the most relevant documents are retrieved. In the generation phase, ML helps the LLM generate more accurate and contextually appropriate responses.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3 serve as the core of RAG, providing the ability to understand complex language, synthesize information, and generate human-like text. They can even go beyond answering questions, generating summaries, reports, and other forms of content.
Natural Language Processing (NLP)
NLP enables RAG to understand the nuances of human language, accurately interpreting queries and extracting relevant information from documents. This ensures that the retrieved information is truly aligned with the user’s intent.
SearchBlox Enterprise Search
The Essential RAG Toolkit for Factual Knowledge
The Essential RAG Toolkit for Factual Knowledge
The Essential RAG Toolkit for Factual Knowledge
– Launch on-premise or the cloud.
– Launch on-premise or the cloud.
–Scalable data infrastructure
–Scalable data infrastructure
–Text and voice search capabilities
–Text and voice search capabilities
RAG vs. Fine Tuning
RAG vs. Fine Tuning
Pulling everything together, a comparison between RAG and Fine-Tuning LLM models can help you identify which model can specifically drive value across the performance frontier.
Pulling everything together, a comparison between RAG and Fine-Tuning LLM models can help you identify which model can specifically drive value across the performance frontier.
Feature
Feature
Knowledge Base
Adaptability to New Information
Response Accuracy
Cost & Complexity
Use Cases
Strengths
Weaknesses
RAG
RAG
Dynamic, external (e.g., databases, knowledge bases)
High (real-time updates)
High (grounded in retrieved information)
Moderate (retrieval overhead)
Question-answering, chatbots, knowledge-intensive tasks
Real-time information, context awareness, reduced hallucinations
Relies on external knowledge quality, potential for latency
Fine-Tuning LLMs
Fine-Tuning LLMs
Static, integrated into the model itself
Low (requires retraining)
Moderate (depends on training data)
High (computationally expensive)
Task-specific optimization (e.g., translation, summarization)
Improved performance on specific tasks
Limited to training data, catastrophic forgetting
Knowledge Base
RAG
Dynamic, external (e.g., databases, knowledge bases)
Fine-Tuning LLMs
Static, integrated into the model itself
Adaptability to New Information
RAG
High (real-time updates)
Fine-Tuning LLMs
Low (requires retraining)
Response Accuracy
RAG
High (grounded in retrieved information)
Fine-Tuning LLMs
Moderate (depends on training data)
Cost & Complexity
RAG
Moderate (retrieval overhead)
Fine-Tuning LLMs
High (computationally expensive)
Use Cases
RAG
Question-answering, chatbots, knowledge-intensive tasks
Fine-Tuning LLMs
Task-specific optimization (e.g., translation, summarization)
Strengths
RAG
Real-time information, context awareness, reduced hallucinations
Fine-Tuning LLMs
Improved performance on specific tasks
Weaknesses
RAG
Relies on external knowledge quality, potential for latency
Fine-Tuning LLMs
Limited to training data, catastrophic forgetting

SearchAI
SearchAI
Feature-rich AI Assistants – Enhancing Engagement. Redefining Performance.
Feature-rich AI Assistants – Enhancing Engagement. Redefining Performance.
Feature-rich AI Assistants – Enhancing Engagement. Redefining Performance.
Optimized for RAG
Optimized for RAG
Optimized for RAG
Set up AI assistants and conversational chatbots using your own data directly on the SearchAI platform.
Fixed Cost
Fixed Cost
Fixed Cost
Significantly reduce costs and complexity; our solutions easily integrate with existing hardware and virtual servers.
Highly Scalable
Highly Scalable
Highly Scalable
Deploy AI models that are scalable across your organization and unlock the full potential of your data.
Secure & Private
Secure & Private
Secure & Private
Keep your model, your inference requests and your data sets within the security domain of your organization.
Enterprise Use Cases for RAG
Enterprise Use Cases for RAG
Relevance and context builds relationships. RAG empowers customers and employees to build trust, transparency and security when accessing generative AI applications.
Relevance and context builds relationships. RAG empowers customers and employees to build trust, transparency and security when accessing generative AI applications.
01
01
01
Customer Service Chatbots
Customer Service Chatbots
RAG-powered chatbots can provide accurate and relevant answers to customer inquiries by retrieving information from knowledge bases, product documentation, or past interactions.
RAG-powered chatbots can provide accurate and relevant answers to customer inquiries by retrieving information from knowledge bases, product documentation, or past interactions.
02
02
02
Question-Answering Systems
Question-Answering Systems
RAG can be used to build question-answering systems that can provide detailed answers to complex questions on a wide range of topics.
RAG can be used to build question-answering systems that can provide detailed answers to complex questions on a wide range of topics.
03
03
03
Content Generation
Content Generation
RAG can generate creative and informative content, such as summaries, reports, or even entire articles, by drawing upon relevant information from external sources.
RAG can generate creative and informative content, such as summaries, reports, or even entire articles, by drawing upon relevant information from external sources.
04
04
04
Knowledge Exploration
Knowledge Exploration
RAG can help users explore and discover new information by providing contextually relevant suggestions and recommendations based on their queries.
RAG can help users explore and discover new information by providing contextually relevant suggestions and recommendations based on their queries.
05
05
05
Enterprise Search Enhancement
Enterprise Search Enhancement
Leveraging platforms like SearchBlox Enterprise Search, RAG can significantly improve the relevance and accuracy of enterprise search results by augmenting queries with contextual information from diverse data sources. This empowers employees to find the information they need quickly and efficiently, leading to increased productivity and informed decision-making.
Leveraging platforms like SearchBlox Enterprise Search, RAG can significantly improve the relevance and accuracy of enterprise search results by augmenting queries with contextual information from diverse data sources. This empowers employees to find the information they need quickly and efficiently, leading to increased productivity and informed decision-making.
06
06
06
Decision Support
Decision Support
RAG can assist decision-makers by quickly summarizing relevant information from various sources and presenting it in a concise and actionable format.
RAG can assist decision-makers by quickly summarizing relevant information from various sources and presenting it in a concise and actionable format.
Feeling overwhelmed?
Feeling overwhelmed?
Feeling overwhelmed?
We can help.
We can help.
We can help.
Schedule a private consultation to see how SearchAI ChatBot will make a difference across your enterprise, distributed teams, and data silos.
Schedule a private consultation to see how SearchAI ChatBot will make a difference across your enterprise, distributed teams, and data silos.

No Hallucinations
No Hallucinations
RAG significantly enhances the factual accuracy of AI-generated responses by grounding them in verified information sources. This significantly reduces the risk of producing misleading or inaccurate outputs, ensuring the reliability of responses.
RAG significantly enhances the factual accuracy of AI-generated responses by grounding them in verified information sources. This significantly reduces the risk of producing misleading or inaccurate outputs, ensuring the reliability of responses.

Contextually Relevant Results
RAG delves into the specific query and context, delivering bespoke responses that directly address user needs. This enhanced personalization elevates the user experience and ensures the information provided is genuinely impactful and relevant.
Contextually Relevant Results
RAG delves into the specific query and context, delivering bespoke responses that directly address user needs. This enhanced personalization elevates the user experience and ensures the information provided is genuinely impactful and relevant.
Expanded Knowledge Base
Expanded Knowledge Base
By integrating with diverse sources of information, RAG extends the reach of LLMs, allowing them to tap into a wider range of knowledge. This means you can ask more complex questions and receive more comprehensive answers.
By integrating with diverse sources of information, RAG extends the reach of LLMs, allowing them to tap into a wider range of knowledge. This means you can ask more complex questions and receive more comprehensive answers.


Adaptability and Versatility
Adaptability and Versatility
RAG is a flexible framework that can be readily adapted to various domains and use cases. By simply updating the knowledge sources, organizations can harness RAG’s power for a diverse range of applications, making it a valuable tool for various business functions.
RAG is a flexible framework that can be readily adapted to various domains and use cases. By simply updating the knowledge sources, organizations can harness RAG’s power for a diverse range of applications, making it a valuable tool for various business functions.

Enhanced Security
RAG maintains data security by operating within your organization’s protected knowledge base. This means sensitive information remains secure and encrypted within your own infrastructure, ensuring adherence to stringent data privacy and security protocols.
Enhanced Security
RAG maintains data security by operating within your organization’s protected knowledge base. This means sensitive information remains secure and encrypted within your own infrastructure, ensuring adherence to stringent data privacy and security protocols.
RAG Benefits
RAG Benefits
Why RAG is a Strategic Investment
Why RAG is a Strategic Investment
Retrieval Augmented Generation (RAG) puts data integrity into action. Learn how organizations can harness the power of their knowledge, leading to a range of transformative benefits.
Retrieval Augmented Generation (RAG) puts data integrity into action. Learn how organizations can harness the power of their knowledge, leading to a range of transformative benefits.
Industry Applications
Industry Applications
Retrieval Augmented Generation in Action
Retrieval Augmented Generation in Action
RAG is helping businesses realize their potential, infusing a data-driven culture where AI drives exponential returns.
RAG is helping businesses realize their potential, infusing a data-driven culture where AI drives exponential returns.
Healthcare
Healthcare
RAG empowers healthcare professionals with the most up-to-date and relevant information. Doctors and nurses can access patient records, research papers, and clinical guidelines in real time, leading to more informed diagnoses and treatment plans.
RAG empowers healthcare professionals with the most up-to-date and relevant information. Doctors and nurses can access patient records, research papers, and clinical guidelines in real time, leading to more informed diagnoses and treatment plans.
Government
Government
Foster transparency and improve internal operations by making public information accessible to citizens and enhancing knowledge sharing among government employees. RAG can instantly synthesize vast amounts of incoming data to answer complex queries accurately.
Foster transparency and improve internal operations by making public information accessible to citizens and enhancing knowledge sharing among government employees. RAG can instantly synthesize vast amounts of incoming data to answer complex queries accurately.
Contact Centers
Contact Centers
RAG-powered chatbots elevate customer service by understanding complex inquiries, referencing real-time product data, and providing tailored solutions based on individual customer history.
RAG-powered chatbots elevate customer service by understanding complex inquiries, referencing real-time product data, and providing tailored solutions based on individual customer history.
Financial Services
Financial Services
Financial institutions leverage RAG to analyze real-time financial data, generate comprehensive reports, and even predict market trends, helping traders and analysts make better-informed decisions.
Financial institutions leverage RAG to analyze real-time financial data, generate comprehensive reports, and even predict market trends, helping traders and analysts make better-informed decisions.
Legal
Legal
With its vast corpus of case law and statutes, the legal field is a natural fit for RAG. RAG-powered systems can assist legal professionals in conducting in-depth research, drafting legal documents, and preparing for cases, saving valuable time and resources.
With its vast corpus of case law and statutes, the legal field is a natural fit for RAG. RAG-powered systems can assist legal professionals in conducting in-depth research, drafting legal documents, and preparing for cases, saving valuable time and resources.
Manufacturing
Manufacturing
RAG optimizes manufacturing processes by enabling AI-powered systems to access real-time production data, equipment manuals, and maintenance logs. This allows for proactive identification of bottlenecks, predictive maintenance scheduling, and efficient troubleshooting.
RAG optimizes manufacturing processes by enabling AI-powered systems to access real-time production data, equipment manuals, and maintenance logs. This allows for proactive identification of bottlenecks, predictive maintenance scheduling, and efficient troubleshooting.
Getting Started
Getting Started
Deploying SearchBlox RAG with Private LLMs
Deploying SearchBlox RAG with Private LLMs
Ready to supercharge your Large Language Model (LLM) with the power of Retrieval Augmented Generation (RAG)? SearchBlox’s integrated platform offers a seamless path to enhance your AI capabilities and deliver unparalleled search experiences, all while maintaining the highest levels of data privacy and security.
Ready to supercharge your Large Language Model (LLM) with the power of Retrieval Augmented Generation (RAG)? SearchBlox’s integrated platform offers a seamless path to enhance your AI capabilities and deliver unparalleled search experiences, all while maintaining the highest levels of data privacy and security.
Get started by downloading SearchBlox Enterprise Search Server based on your operating system. The installation guide for each OS will run you through the minimum requirements as well as a step-by-step process in getting started with SearchBlox.
Get started by downloading SearchBlox Enterprise Search Server based on your operating system. The installation guide for each OS will run you through the minimum requirements as well as a step-by-step process in getting started with SearchBlox.
Here’s your roadmap to deploying SearchBlox RAG with Private LLMs:
Here’s your roadmap to deploying SearchBlox RAG with Private LLMs:
Here’s your roadmap to deploying SearchBlox RAG with Private LLMs:
Define Your RAG Objectives
Choose Your Deployment Environment
Choose Your Deployment Environment
Curate Your Knowledge Base
Integrate SearchBlox Private LLM
Build Your Semantic Search Index
Empower your RAG with SearchAI Tools
Empower your RAG with SearchAI Tools
Fine-Tune and Optimize
Monitor, Analyze, and Improve:
Embrace the Future of AI-Powered Search:
Put Data Integrity into Action
Create Value and Build Trust with RAG
Create Value and Build Trust with RAG
Reshape your consumer relationship with your data. Infuse speed, accuracy, ease of access, and trust when retrieving information from your ever-expanding knowledge sources.
Reshape your consumer relationship with your data. Infuse speed, accuracy, ease of access, and trust when retrieving information from your ever-expanding knowledge sources.
Enhance your users’ digital experience.
Security & Compliance
Certifications




SearchAI is SOC 2 attested, HIPAA aligned, ISO/IEC 27001:2022 certified and ISO/IEC 42001:2023 certified.
We build AI-driven software to help organizations leverage their unstructured, and structured data for operational success.
4870 Sadler Road, Suite 300, Glen Allen, VA 23060 sales@searchblox.com | (866) 933-3626





Still learning about AI? See our comprehensive Enterprise Search, Knowledge Graph 101, RAG 101, ChatBot 101, and AI Agents 101 guides.
©2026 SearchBlox Software, Inc. All rights reserved.
Enhance your users’ digital experience.
Security & Compliance
Certifications
SearchAI is SOC 2 attested, HIPAA aligned, ISO/IEC 27001:2022 certified and ISO/IEC 42001:2023 certified.
We build AI-driven software to help organizations leverage their unstructured, and structured data for operational success.
4870 Sadler Road, Suite 300, Glen Allen, VA 23060 sales@searchblox.com | (866) 933-3626
Still learning about AI? See our comprehensive Enterprise Search, Knowledge Graph 101, RAG 101, ChatBot 101, and AI Agents 101 guides.
©2024 SearchBlox Software, Inc. All rights reserved.
Enhance your users’ digital experience.
Security & Compliance
Certifications
SearchAI is SOC 2 attested, HIPAA aligned, and ISO/IEC 27001:2022 certified.
We build AI-driven software to help organizations leverage their unstructured, and structured data for operational success.
4870 Sadler Road, Suite 300, Glen Allen, VA 23060 sales@searchblox.com | (866) 933-3626
Still learning about AI? See our comprehensive Enterprise Search, Knowledge Graph 101, RAG 101, ChatBot 101, and AI Agents 101 guides.
©2026 SearchBlox Software, Inc. All rights reserved.