

“FAQs” exist to make it easy to find information. Their purpose is to deflect as many support calls as possible. Organizations invest staff hours and dollars to create and maintain lists of Frequently Asked Questions in hopes they will support self-service.
But for companies with complex offerings, users rarely have simple, straightforward questions. Moreover, users rarely ask questions in the same way. Instead of ‘FAQs’, the hard-coded lists become “our best guess at what users are asking.” Without context and feedback, users can’t find what they need. And organizations are blind to what’s missing.
It begs the question, are FAQs serving anyone?
Today, AI-powered technology presents an opportunity to challenge the old model of FAQs. Read on to learn what’s possible for today’s users and content managers. We’ll go over:
A brief history of FAQs
What’s wrong with traditional FAQs
How SmartFAQs™ helps people find the right information FASTER.
The History of FAQs: How Did We Get Here?
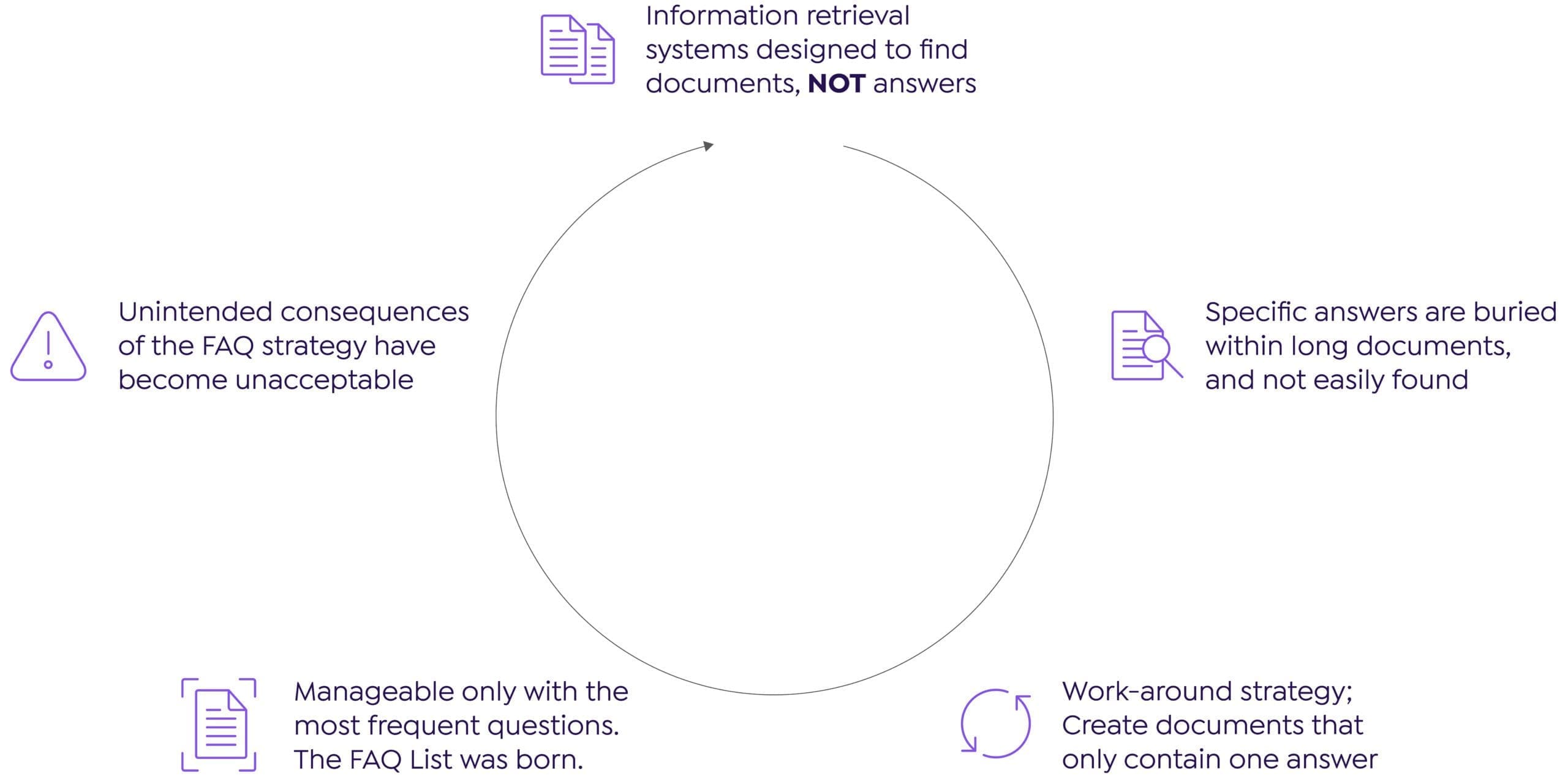
Before FAQs, ‘Information Retrieval Systems’ helped employees find data they needed. An internal user performed a search and received lists of indexed documents. The user then scoured those large documents to search for the right answer.
The process was cumbersome. For faster access, content owners started making shorter documents with the specific answers. Each “shortcut” document was indexed as a new, individual piece of content. Finally, users collected the short docs into a list of “frequently asked questions.”
Unfortunately, more documents meant more document management. It was easy for the new, shorter documents to get out of sync with the larger source content. Often, different users needed different snippets of information for their context. More documents were generated. Before long, the number of answers needed far exceeded a succinct list of questions.
As the digital era enabled greater levels of self-service, the case for FAQs grew. They became the standard we know today, but with unintended consequences which have led us full circle, back to the original assumption related to directly finding answers within documents.
What’s Wrong with Traditional FAQs?
The challenges associated with standard FAQs for complex organizations are annoying to consumers and costly for organizations:
1. Questions are asked in lots of ways.
FAQs are manually produced based on assumptions of the frequency of specifically worded questions.
Hard coded questions can’t account for variations in how the questions are naturally asked by the user.
There’s no way to determine context for the question and direct the user down the right path automatically.

2. Duplicate content gets out of sync.
Manually produced FAQs are usually copy snippets from a larger document.
End-users might discover duplicate or competing organizational content.
Shared answers may be out of compliance, putting the company at risk.
There’s no way to flag what’s changed and easily fix it across all channels.
3. It’s hard to spot (and correct) searches that produce dead-end logic.
Manually produced FAQs are typically the shortest possible answer, with no additional context. It’s up to users to rework their questions in order to circle closer to what they’re looking for (i.e. waste time).
The organization is blind to breakdowns in communication that lead to customers searching the FAQs in the first place.
An example:
Let’s say a bank sends a billing envelope with the company’s address on it to a customer. What does it mean if that customer goes to the website to ask for the billing address? Did they just need the address or something else? Why didn’t they have what they needed with the envelope? How would anyone know?
An example:
Let’s say a bank sends a billing envelope with the company’s address on it to a customer. What does it mean if that customer goes to the website to ask for the billing address? Did they just need the address or something else? Why didn’t they have what they needed with the envelope? How would anyone know?
These challenges mean that even with FAQs painstakingly created and expensively maintained, organizations still need a human interpreter in the middle to help answer questions with any degree of complexity.
The limitations of traditional FAQs make it hard to do a true cost/benefit analysis of having and maintaining them:
- How many call center calls are actually being avoided?
- How much money and good will is being left on the table when people just give up in frustration?
- How many errors go unspotted or cause a ripple of more expensive problems to solve?
- How often are FAQs ignored altogether?
Leaders are left guessing most of the time.
SmartFAQs™: Better for Customers and Organizations
As described, traditional FAQs came about because a source document containing the answer was the smallest, searchable object. It was cumbersome, if not impossible, to find specific information hidden in pages and pages of documentation. We’ve operated with this same line of thinking for decades.
It’s time for a paradigm shift.
SmartFAQs™ is an AI-powered tool that crawls source documents and automatically generates context-rich questions for existing information snippets. When a user does a search, even with one of two keywords, SmartFAQs provides a list of questions and answers related to the search keyword(s).
SmartFAQs™ creates thousands of questions and answers covering the whole gambit of information contained in the source documents.
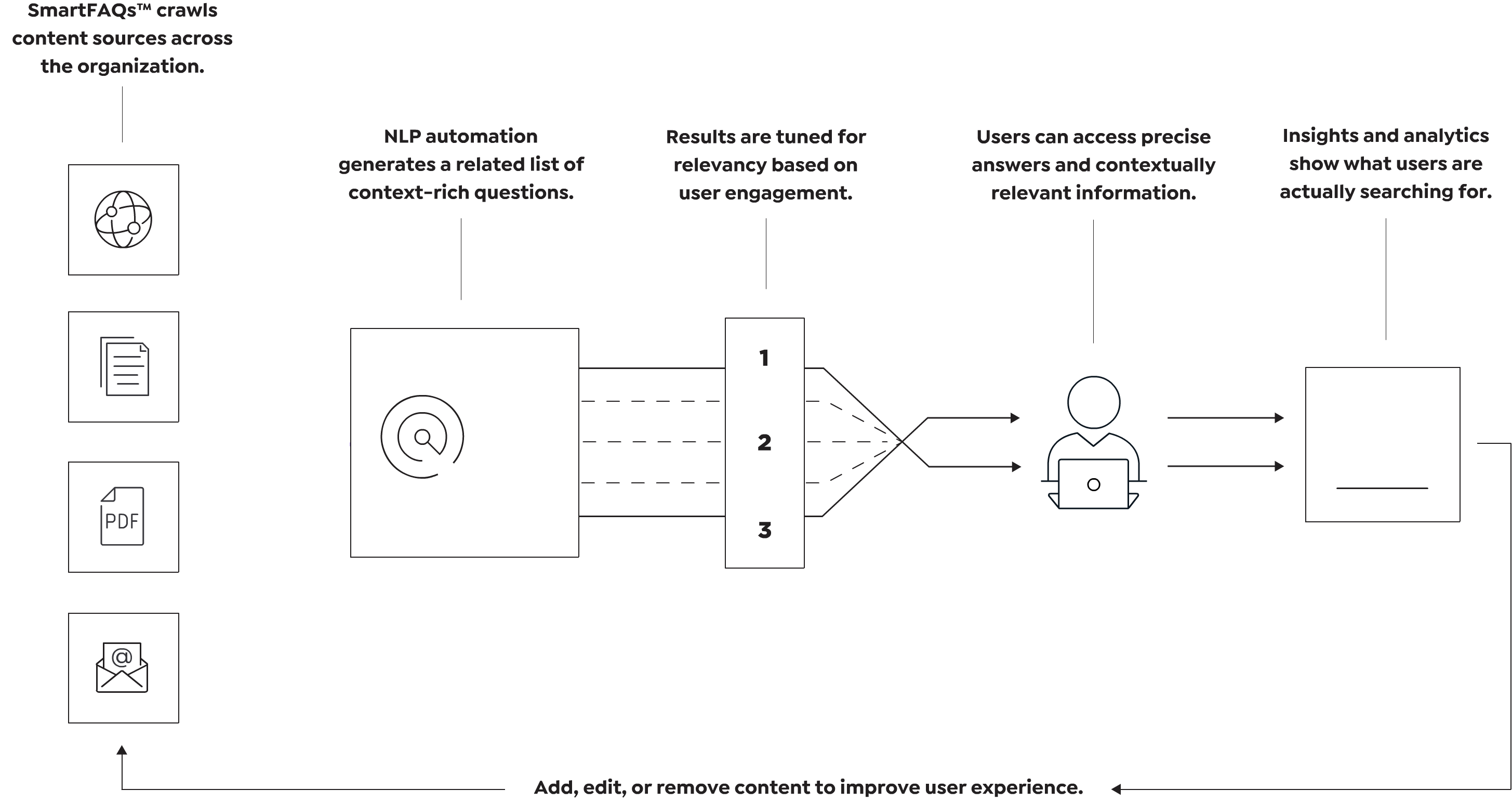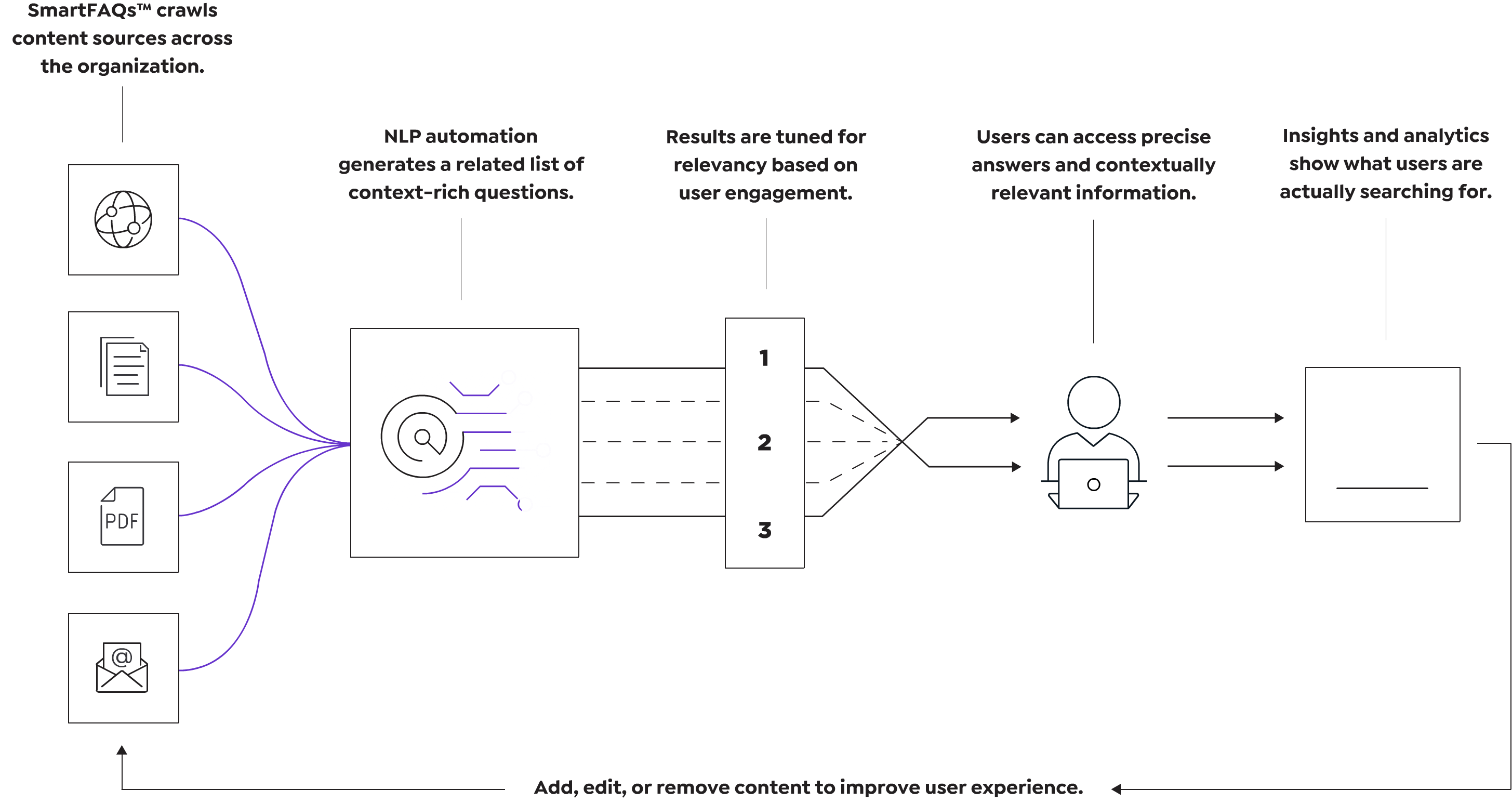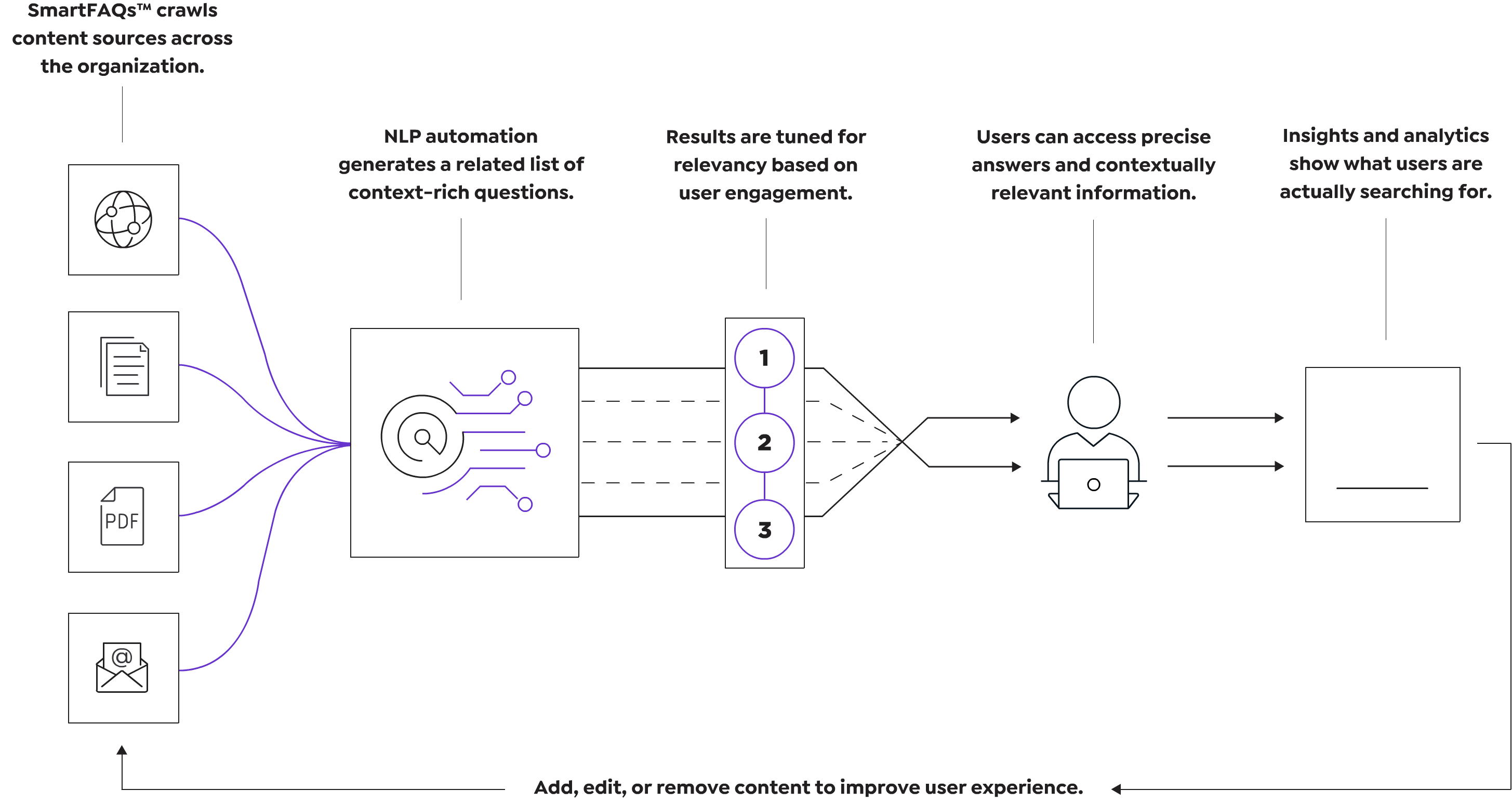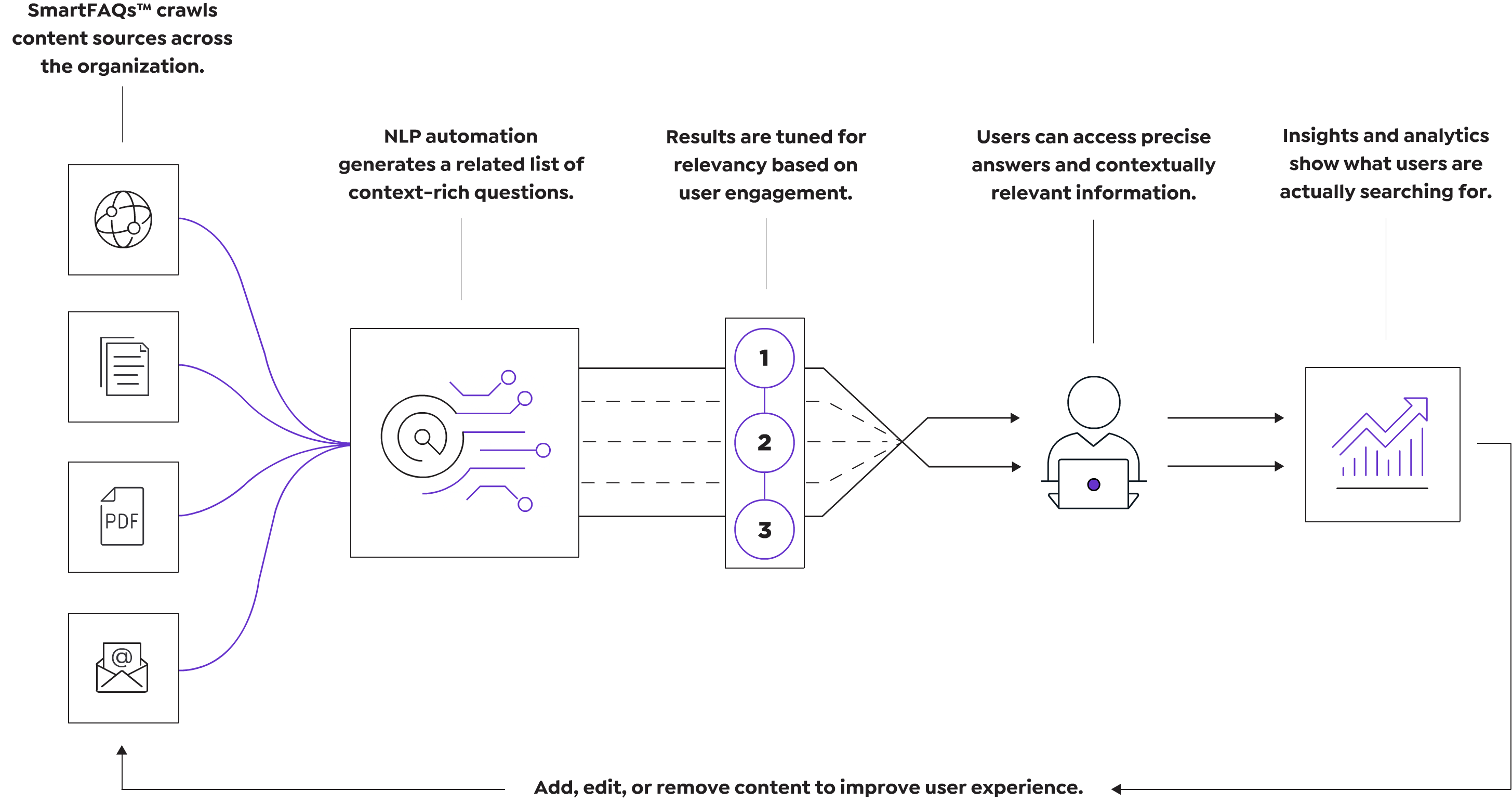
The result is that users get what they’re looking for, and organizations see additional benefits:
- Automatically generate FAQs
- Stop predicting what users might need: pull answers from the entire range of content
- Keep answers in sync with source document content
- Provide precise answers and other related links for easy navigation
- Integrated with intelligent search results so that users don’t have to check on multiple pages on the website
Management is easier, too.
- Search managers can easily add, remove, or edit questions and answers
- Analytics & Insights to show user engagement with SmartFAQs™ and highlights ways to improve.
- Automatically flag SmartFAQs™ when the source content changes , minimizing compliance risk
Conclusion
Customers and companies all turn to FAQs for the same reason: to avoid time spent on service calls. SmartFAQs™ help customer-experience driven organizations dramatically improve self-service in ways that simply were not possible in the past. More than that, organizations benefit from time and cost savings as well as reduced compliance-related risks.
